
Med big data kan man kasta ut teori och i stället låta datan tala för sig självt. Kausalitet är död och korrelation är den nya herren på täppan. I denna text ska jag försöka förklara varför en sådan inställning är helt fel.
Vad är big data?
Vi kan börja med att förklara vad big data är. Wikipedia säger att big data är ”data sets that are so large or complex that traditional data processing applications are inadequate”. Ett sådant begrepp är alltid relativt till den teknik vi har för tillfället, och ibland också den enskilda person som hanterar datan. Således är det som är big data i dag inte det som är big data i morgon.
Använder man en relationsdatabas är det dock ingen större konst att hantera miljoner eller miljarder rader på en vanlig laptop, om varje rad inte tar speciellt mycket utrymme. Det finns dock extrema exempel, såsom Large Hadron Collider som skapar flera petabyte per år (1 petabyte är 1 miljon gigabyte) och kräver flera datacentrar för att bearbeta all data.
Big data år 1936
Big data är dock knappast något nytt om man bara menar datamängder större än normalt. Redan 1936 genomfördes en opinionsundersökning med över tio miljoner personer (varav 2,5 miljoner svarade) för att ta reda på vem som skulle bli USA:s nästa president. Problemet var att bara personer med bil eller telefon fick svara på undersökningen, vilket uteslöt en stor del av den fattiga befolkningen. Föga förvånande (åtminstone i efterhand) fann man att republikanernas presidentkandidat skulle vinna storslaget, vilket sedan visade sig vara precis tvärtom mot det riktiga resultatet.
Funna datamängder
Det jag däremot ska prata om i den här texten är funna datamängder (found data), vilket är sådan data som redan finns och som forskaren så att säga ”hittar”. Det kan vara att analysera meddelanden på Twitter eller Facebook, vilka sökningar folk har gjort i en sökmotor, eller deras geografiska position som telefonen avslöjar.
Dessa funna datamängder kan man sätta i konstrast till data som man själv har skapat, till exempel data från ett vetenskapligt instrument (såsom fMRI eller Large Hadron Collider) eller ett vanligt experiment.
Överdrivna påståenden om big data
Chris Anderson är väl en av dem som gått längst med att beskriva fördelarna med big data, till exempel i artikeln The End of Theory: The Data Deluge Makes the Scientific Method Obsolete:
This is a world where massive amounts of data and applied mathematics replace every other tool that might be brought to bear. Out with every theory of human behavior, from linguistics to sociology. Forget taxonomy, ontology, and psychology. Who knows why people do what they do? The point is they do it, and we can track and measure it with unprecedented fidelity. With enough data, the numbers speak for themselves.
Vi kan alltså kasta ut teorier om varför någonting händer och i stället bara observera att det händer. Han säger vidare att korrelation till och med ersätter kausalitet:
The new availability of huge amounts of data, along with the statistical tools to crunch these numbers, offers a whole new way of understanding the world. Correlation supersedes causation, and science can advance even without coherent models, unified theories, or really any mechanistic explanation at all.
Chris Anderson är kanske det mest extrema exemplet så vi kan ignorera hur pass representativt det är. Men bristen på kritik mot big data riskerar att göra påståenden överdrivna, så kritik tjänar åtminstone till att inskränka möjligheterna och tydliggöra begränsningarna med big data.
Tre vanliga historier om big data
Det finns tre vanliga anekdoter som ibland berättas om big data. Dessa ska jag kort redogöra för nedan och sedan beskriva problemen med dem.
Google Flu Trends som förutspådde influensaepidemier
Google lanserade under 2008 tjänsten Google Flu Trends som förutspådde influensaepidemier genom sökningar på deras sökmotor (läs mer i Detecting influenza epidemics using search engine query data i Nature).
Den förutspådda influensaepidemin jämfördes sedan med de ”riktiga” värdena som rapporterats in av amerikanska CDC, eller Centers for Disease Control and Prevention som är det fullständiga namnet (vilket motsvarar svenska Smittskyddsinstitutet och Folkhälsomyndigheten). Siffrorna från CDC hade ungefär två veckors dröjsmål sedan de rapporterats in av landets alla vårdinrättningar, så att kunna förutspå influensaepidemier skulle ha stora fördelar för samhället, inte minst ekonomiska.
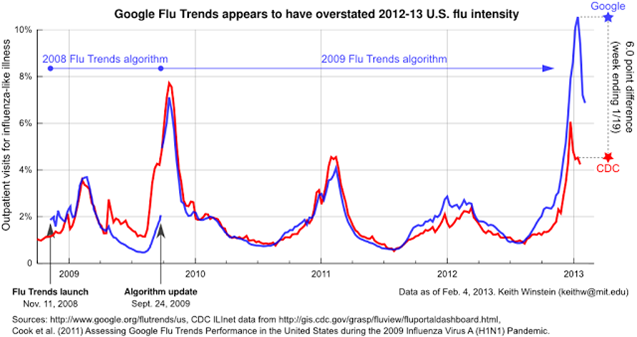
Träffsäkerheten på Google Flu Trends var dessutom väldigt hög, åtminstone inledningsvis. Dessvärre började Flu Trends att kraftigt underrepresentera den verkliga prevalensen av influensa, varpå Google justerade algoritmerna. Men till slut började Flu Trends i stället att kraftigt överrepresentera prevalensen av influensa. Inte så långt därefter lade Google ned tjänsten helt och hållet.
Street Bump och gropar i vägen
En annan anekdot kommer från 2012 då projektet Street Bump lanserades. Vägarna i Boston hade en mängd gropar och ett av problemen för att åtgärda dem var att helt enkelt hitta dem.
Ett väldigt kreativt sätt var att skapa en app som sedermera kom att kallas Street Bump. Appen låter förare automatiskt rapportera gropar i vägen genom att utnyttja sensorerna (accelerometern) som känner av rörelsen när bilen hoppar till av groparna i vägen.
Dessvärre rapporterades mängder av gropar felaktigt därför att appen inte lyckades skilja riktiga gropar från ”fantomgropar”. Men detta åtgärdades relativt snabbt med bättre programvara.
Target och den gravida tjejens pappa
En annan vanlig anekdot som ofta berättas är hur den amerikanska dagligvarukedjan Target skickade anpassad reklam för blivande mammor direkt till en tonårstjej. Tjejens pappa blev rasande och gick till affären för att i starka ordalag säga vad han tyckte om reklamen. Affären bad om ursäkt.
Efter ett par veckor ville affärsägaren återigen be om ursäkt och ringde upp tjejens pappa. Pappan var dock inte lika arg längre och sa i stället att Target hade rätt – hon var gravid. Pappan hade däremot inte fått reda på det. Med andra ord visste Targets algoritmer något som inte pappan visste.
6 problem med big data
1. Korrelation är inte kausalitet
Detta är knappast något nytt, men kanske det mest uppenbara och värt att poängtera ånyo. Nu har förvisso Chris Anderson sagt att det inte har någon betydelse, eftersom korrelation av någon anledning ersätter kausalitet förutsatt att man analyserar tillräckligt stora datamängder.
Dessvärre är hans exempel inte speciellt övertygande. Han nämner biologer som analyserar gendata och lyckas hitta skillnader. Men biologer är inte direkt kända för att förhålla sig kritiska till big data, åtminstone inte enligt artikeln Big data and the historical sciences: A critique, och statistiska signifikanta skillnader i gendata är inte tillräckligt för att skapa taxonomier av arter eller liknande.
Det finns exempelvis en positiv korrelation mellan smörkonsumtion och skilsmässor. Men vad ska vi göra med den informationen, förutom att roas åt den?
2. Vi får inte reda på falska positiva
Ett problem med historien om Target är att vi inte får veta hur stor andel av den anpassade reklamen för blivande mammor har skickats till de som inte är blivande mammor. Det vill säga, vi får inte reda på andelen typ 1-fel (falska positiva). Det är avgörande för att kunna bedöma hur pass tillförlitlig algoritmen är.
Detta är särskilt viktigt när det gäller kommersiella företag som inte vill, kan eller får dela med sig av den data de analyserar. Vi har helt enkelt ingen insyn och får helt enkelt lita på deras ord att det fungerar.
3. Algoritmer skapar självuppfyllande profetior
Så fort vi har en algoritm som kan påverka mänskligt beteende så kan den också skapa en självuppfyllande profetia.
Amazon har exempelvis en algoritm som visar ”de som har köpt den här boken har också köpt …” En sådan algoritm syftar naturligtvis till att öka försäljningen av böcker, men det innebär också att det som föreslås även köps i högre utsträckning. Med andra ord, det som algoritmen använder som underlag för att fatta beslut är det som till slut matas in i algoritmen igen, vilket skapar en ömsesidig förstärkning. Enkelt uttryckt: Det populära blir populärare därför att algoritmen har föreslagit att det ska vara populärare.
Därmed kommer framgångarna med denna typ av algoritmer att vara överdrivna. I fallet med Amazon gör det ingenting eftersom målet är att sälja mer böcker, men i andra fall av mänskligt beslutsfattande kan de hjälpa till att subtilt påverka beslut när beslutsfattarna saknar kunskap om algoritmernas förstärkningseffekter.
4. Det finns sällan teori som förklarar
Varför fungerade Google Flu Trends? Vi vet inte. Varför slutade Google Flu Trends att fungera? Det vet vi inte heller av samma anledning.
Eftersom det inte finns någon underliggande teori om hur eller varför saker och ting beter sig som de gör, är det ännu svårare att förklara varför något slutar fungera.
När det gäller Google Flu Trends kan det mycket väl vara så att medierna påverkar vad människor tänker på, och därmed vad de söker efter. Ju mer medierna skriver om influensa, desto mer söker alltså människor efter influensaliknande symptom. Det är en teori man kan testa på olika sätt, och ger också förutsägelser för vad man teoretiskt kan förvänta sig och därmed också de förutsättningar där teorin kan vara felaktig.
Det är en viktig distinktion eftersom flera big data-förespråkare tycks mena att vi ska analysera stora datamängder för att utvinna informationen som råkar finns där, snarare än att man utgår från en teori och testar om man kan hitta data som man förväntar sig finna där.
5. Data talar inte för sig självt
Data talar aldrig för sig själv utan kräver tolkning. Tolkning är beroende på dels statistisk kunskap, dels ämneskunskap och dels sammanhang. Det må finnas ett samband mellan två variabler i en datamängd, men det sambandet kan vara helt meningslöst ur teoretisk synvinkel och kanske förklaras av något annat som inte ingår i datamängden, men som ändå var närvarande i det sammanhang som datan samlades in. Utan hänsyn till sammanhang riskerar big data förblinda mer än upplysa.
6. Tron att om man har all data så har man alla svaren
Det finns ett uttryck om att big data betyder n = allt, vilket innebär att man analyserar all data som finns (och inte bara data man kan få tillgång till). Därmed behöver man inte göra ett urval eftersom man kan analysera allt. Det kan leda till följande villfarelser:
”Halva svenska befolkningen finns på Facebook. Därför kan man också se vad (åtminstone halva) svenska folket gör, tycker eller tänker genom att analysera Facebookdata.”
Fel!
Även om varenda svensk fanns på Facebook skulle en analys av bokstavligt talat all Facebookdata ändå inte innehålla en beskrivning av alla svenskar, utan bara aktiva svenskar. Det brukar kallas activity bias och riskerar ge väldigt skeva resultat.
Antalet konton på Facebook säger heller ingenting om antalet svenskar. Jag har exempelvis två konton på Facebook samt fyra-fem konton på Twitter för olika projekt. Många konton används för att automatiskt publicera inlägg.
När det gäller appen ”Street Bump” kan man fråga sig vilka det är som framför allt äger smartphone och bil? Det är inte de fattiga i alla fall, vilket leder till att gropar i de välbärgade områdena rapporteras in i betydligt högre utsträckning än mindre välbärgade områden. Det behöver dock inte nödvändigtvis vara ett problem, utan kan snarare frigöra resurser att faktiskt åka ut och leta efter gropar i vägen i andra områden. Men då måste man också vara medveten om begränsningarna.
Allt går inte att mäta
Jag tror inte någon förnekar att big data (hur man än definierar det) har lett eller kommer leda till en mindre revolution. Men absolut inte i meningen att vi kan kasta ut teorier om kausalitet, utan snarare att mängden data från samhällets alla hörn gör att vi kan ägna oss åt betydligt fler analyser. Inte minst med mobiltelefonernas sensorer!
Men samtidigt är det viktigt att inte förlora den humanistiska aspekten. Allt går inte att mäta, och allt man mäter behöver inte vara värdefullt. Just frågan kring hur man ska tolka data och ge den mening är knappast något som blir mindre problematiskt när vi badar i data. Snarare tvärtom. Det är lätt hänt att vi blir blinda för alternativa synsätt (som inte bygger på analys av mer och mer data) när vi redan drunknar i data.
Vi måste fortfarande ha teorier och vi måste fortfarande beakta det som kanske inte ens bör mätas, som till exempel normativ etik. Om man till exempel mäter konsekvenser av en handling (låt säga hur mycket pengar någon ger tiggare) så säger man implicit att konsekvensetik är det vi ska föredra framför dygd- eller pliktetik. Som sagt, bara för att det går att mäta innebär det inte att det bör mätas eller ens tillmätas någon betydelse. Det är fortfarande en teoretisk fråga, inte en empirisk.
Slutsats
Min poäng med denna text är inte att vi ska sluta analysera ”big data” eller sluta se möjligheterna med det, utan snarare att försöka blottlägga ett oreflekterat analyserande av big data och i stället lyfta fram begränsningarna. Det hjälper oss att se när vi faktiskt bör analysera big data.
Problemet med ”funna data” kan egentligen sammanfattas på ett enkelt sätt. Så fort man försöker mäta människors beteende så kan människor anpassa sig efter mätningen. Då kan en feedback-loop uppstå, vilket innebär att information om mätningen påverkar fortsatta mätningar. Ett bra exempel är artikeldelningar. Vi tenderar att dela artiklar som redan har delats mycket. Konsekvensen är att det populära blir ännu mer populärt.
Big data är inte heller slutet för teori. Teori är viktigare än någonsin för att sortera bland, och framför allt förstå, big data.
Jag tror att vi kommer få se många fler analyser inom både journalistiken och vetenskapen som är exakt fel. På 1960-talet sa den amerikanska matematikern John Tukey att han föredrog ‘‘an approximate answer to the right question, which is often vague, than an exact answer to the wrong question, which can always be made precise”. Med andra ord kanske vi ska ställa mer precisa frågor och sedan se om de kan besvaras med big data, snarare än att titta i big data först och se vilka frågor vi kan besvara exakt.