I min tidigare artikel om Big data: hur man mäter exakt fel beskrev jag problemet med att ge avkall på sitt kritiska tänkande eftersom datamängden är så pass stor att blotta storleken på något magiskt vis gör att problem försvinner. I synnerhet när det gäller data som handlar om människor och deras sociala relationer.
I denna artikel tänker jag fortsätta på den linjen och ge två exempel där journalister har en förutbestämd tolkning de lägger till datan, snarare än att de hämtar tolkningen från datan. De två olika tillvägagångssätten kan kanske bäst sammanfattas med teckningen nedan. För den som inte känner till så är kreationism tron att Gud skapade världen.

The scientific method: Here are the facts. What conclusions can we draw from them?
The creationist method: Here’s the conclusion. Whats facts can we find to support it?
Exempel 1. Kit analyserar den hatiska flyktingopinionen
Den relativt nystartade nyhetssajten Kit skriver i artikeln Så sprids flyktinhatet på nätet exakt hur omfattande hatet (och även rädslan) mot just flyktingar är. Nedan följer ingressen samt det inledande stycket från nyhetssajten.
Man kan fråga sig hur denna analys har gått till, och Kit är vänliga med att presentera den för oss (med mina fetmarkeringar):
Allt som publiceras öppet på nätet i en viss fråga sparas och blir sökbart. Inläggen klassificeras utifrån vilka ord som förekommer i samband med det tema som analyseras. När det gäller ”flyktingar” är det alltså inlägg i flyktingfrågan som räknas, så hatet behöver inte vara riktat mot flyktingar, det kan även vara riktat mot exempelvis politiker som fattat beslut i flyktingfrågan. För varje tonalitet finns några tusen ord. När det gäller hat är det ord som ”avsky”, ”hata”, ”förakta”, ”föröda”, ”bua”, ”pervertera” osv.
Inlägg klassas som positiva när det förekommer ord som ”bra”, ”cool”, ”snygg”, ”najs” Även olika typer av smileys räknas.
Metoden tillåter alltså att man mäter hur ofta två typer av ord förekommer tillsammans, då företrädesvis flyktingar och hatiska ord. Det har Kit sedan valt att tolka som att det är hat riktat mot flyktingar. Det finns dock ingenting i metoden som tillåter den tolkningen, eftersom en fras som ”jag hatar politiker som inte hjälper flyktingar” är riktat mot politiker till stöd för flyktingar.
En metod medger vissa tolkningar men inte andra. Det är så med alla metoder och det är därför vi måste ha flera metoder som fungerar som ett lapptäcke och i den bästa av världar ger ett samstämmigt resultat. För att kunna dra slutsatser från en analys av detta slag måste man därför ha kunskaper vad en metod faktiskt kan göra (och kanske mer viktigt, vad den inte kan göra) för att kunna berättiga en slutsats. I det här fallet har Kit ignorerat begränsningarna genom att göra om ett samband mellan ord till ett orsakssamband som ska tolkas på ett specifikt vis. Enkelt uttryckt har ”hat och flyktingar” blivit ”hat mot flyktingar”.
Det tycks dock ligga någon sorts vinst i att det åtminstone går att mäta detta hat exakt eftersom Kit menar att de nu kan visa ”exakt hur omfattande det är”. Men det är mer sannolikt ett exakt mått på fördomen som journalisten hade i huvudet när datan analyserades.
För den som är intresserad av den här frågan kan jag hänvisa till en diskussion på Twitter jag hade med journalisten ifråga. Mina frågor om huruvida metoden tillåter denna slutsats besvaras dock inte (förmodligen på grund av att vi inte förstod varandra, en inte helt ovanlig situation på Twitter).
Exempel 2. Guardian analyserar 70 miljoner kommentarer
Ett annat exempel kommer från den brittiska tidningen The Guardian, som för en tid sedan publicerade The dark side of Guardian comments. Tidningen analyserade 70 miljoner kommentarer på sin nyhetssajt sedan 2006 och kom fram till att artiklar som är skrivna av kvinnor innehöll fler blockerade kommentarer än de som var skrivna av män. Blockerade kommentarer raderades alltså inte, utan doldes bara för visning eftersom de bröt mot tidningens regler. De raderade dock kommentarer som innehöll spam och dylikt.
Det mest intressanta är förmodligen det tredje diagrammet i artikeln, som visar vilka journalister (män eller kvinnor) som fått flest kommentarer blockerade till sina artiklar. Diagrammet visar att upp till 2,6 procent av kommentarerna har blockerats från artiklar skrivna av kvinnor (vilket också är uppdelat per sektion). Motsvarande siffra för män är 1 procent. Skillnaden mellan könen är maximalt 3 procentenheter och återfinns år 2013. (Detta är en uppskattning eftersom jag mätt pixlarna i de färgade linjerna i diagrammet där 60 pixlar motsvarar ungefär 1 procentenhet.)
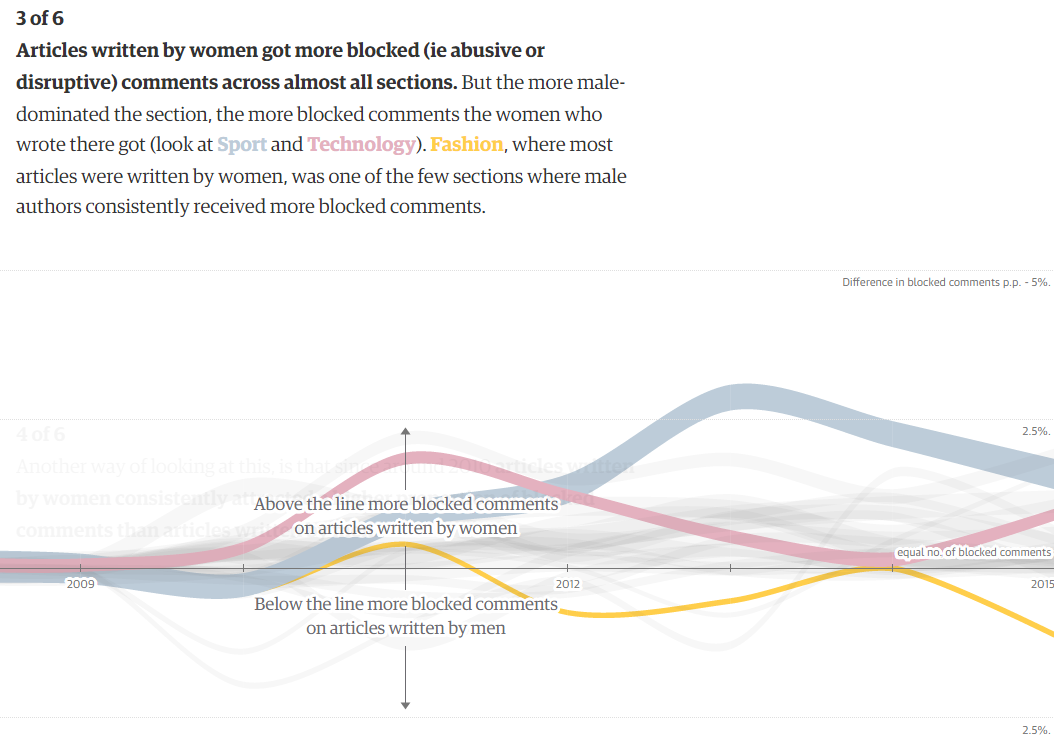
Detta är ett intressant fynd även om det inte är speciellt stor skillnad. Men det är viktigt att ha i åtanke att detta bara är ett samband mellan journalistens kön med kommentarer som blockerats. Samband betyder inte orsakssamband. Vi vet därför inte varför sambandet ser ut som det gör.
Vi vet heller inte vad det är för slags kommentar som blockerats. Guardian ger inte speciellt ingående analys av vad för slags kommentarer det handlar om. Jag har läst texten och sammanställt deras beskrivning i tabellen nedan:
| Typ av kommentar som blockerats | Andel av kommentarerna |
|---|---|
| legal | small proportion |
| disruptive | vast majority |
| – disruptive: threats | extremely rare |
| – disruptive: dismissive trolling | |
| – disruptive: author abuse | significant proportion |
| hate speech | rarely seen |
| xenophobia, racism, sexism and homophobia | seen regularly |
| “whataboutery” | |
| Totalt antal kommentarer: | 70 miljoner |
(Tomma rutor indikerar att Guardian inte skrev andelen eller frekvensen.)
Sammanfattningsvis finns det mellan 0-3 procentenheters skillnad mellan könen, och de största skillnaderna återfinns snarare mellan typ av ämne.
Detta hindrar dock inte Guardian från att dra följande slutsats: ”of the 10 most abused writers eight are women, and the two men are black” (återigen mina fetmarkeringar). Men Guardian är för ivriga att sätta ett likhetstecken mellan hat mot journalister och antalet blockerade kommentarer. Guardian har över huvud taget inte analyserat vad kommentarerna innehåller utan bara hur många kommentarer som blockerats från kvinnliga respektive manliga journalisters artiklar. Och det är en tämligen trivial räkneövning som inte säger speciellt mycket.
Guardians metod och källkod finns beskrivet på deras hemsida, där de också skriver att ”we took blocked comments as an indicator of abuse and/or disruption”. Det vill säga, om en kommentar har blockerats så räknas den som kritik mot journalisten oberoende vad den innehåller. Men de blockerade kommentarerna kan dock mycket väl vara riktade mot någon helt annan än journalisten. Till exempel kan två kommentatorer växelvis kalla varandra idioter genom 200 ömsesidiga meddelanden (en inte helt osannolik situation för den som följt sociala medier). Men det innebär inte att journalisten som skrivit artikeln har blivit kallad idiot 200 gånger.
Precis som i fallet med Kit sker här en förväxling till fördel för den tolkningen som tycks vara närvarande i journalistens huvud snarare än i den data som analyseras. I det här fallet har ”blockerade kommentarer” blivit ”kommentarer som trakasserar journalister”.
Och det är fel.
Big data kan på detta sätt användas för att ge mycket exakta svar på frågor ingen har ställt. Med det menar jag att det inte är ursprungsfrågorna som människor funderar över som faktiskt ställs till datan, utan man ställer frågor som låter sig besvaras med hjälp av datan, och tolkar sedan det som ett svar på den ursprungliga frågan. Men det är fusk, eller till och med påhitt skulle jag vilja säga.
Journalistik kontra vetenskap
I forskarspråk pratar man om validitet. I båda exemplen ovan handlar det om att den teoretiska definitionen (hat och hot mot flyktingar respektive journalister) bör stämma överens med den operationella definitionen (det som faktiskt mäts). Här konstruerar journalisterna implicit både en teoretisk definition genom att prata om hat (och dylikt) samt en operationell definition genom mätandet, men det sker ingen större ansträngning att förena dem. I stället antas de vara förenade.
I värsta fall används data bara för att bekräfta journalisternas fördomar om verkligheten. Man kan tro att journalister är utsatta för hat och att antalet kommentarer är det objektiva beviset. Men det vore ingen analys, utan bara en form av cirkelbevis som döljs i pratet om hur stor datamängden är.
”Men vi gör inte anspråk på att vara vetenskapliga!” är en invändning från journalister.
Det är sant, det är viktigt att inte förväxla journalistik med vetenskap. Men när journalister förlitar sig allt mer på stora datamängder som de själva samlar in och analyserar ställer det krav på att analysen genomförs på ett korrekt sätt för att de ska kunna dra giltiga slutsatser. Det är det logik handlar om, att dra slutsatser från påståenden. Att logik används inom vetenskapen innebär inte att det är förbehållet vetenskapen eller ens att det endast bör förekomma där. Snarare tvärtom. Det är inte så att frasen ”vi håller inte på med vetenskap” är ett frikort till att dra slutsatser som inte låter sig dras från de metoder som används. Det vore absurt att hävda att 1+1=3 för att jag inte gör anspråk på att vara matematiker.
Men det tycker tydligen inte Guardian som skriver ”Even allowing for human error, the large number of comments in this data set gave us confidence in the results.” Med andra ord, även om Guardian gör fel så innebär antalet kommentarer att Guardian är säkra på sitt resultat.
Det tycks, i mina ögon, vara en övertro på stora datamängder kan ge oss en särskild insikt som små datamängder inte kan ge oss, och att problem enkelt försvinner med ökad storlek. Men det är viktigt att skilja mellan slumpmässiga fel som uppstår lite här och var (som namnet antyder) och mellan systematiska fel som uppstår med en viss regelbundenhet. Den stora datamängden kan hjälpa till att minimera slumpmässiga fel (jämför centrala gränsvärdessatsen). Men stora datamängder minimerar aldrig systematiska fel. De systematiska felen kvarstår oberoende av storleken på datamängden av det enkla skälet att de inte har ett dugg med storleken att göra.
Designen av en studie och hur insamlingen av data går till är ofta mycket viktigare än storleken på det insamlade materialet. Ett exempel är randomiserat kontrollexperiment som kan generera så lite som 50 datapunkter, men ändå ge betydligt högre säkerhet i vad som är orsak och verkan på grund av sin design. En analys med väldigt stor osäkerhet blir inte automatiskt säkerställd (i valfri mening av begreppet) bara för att det råkar vara många nollor efter de första siffrorna.
Slutsats
Sluta tro att storleken på en datamängd är något speciellt.
Det är teori, design och analys som är det viktigaste. Gör man dessa slapphänt blir också slutsatsen slapphänt.
Det är vanskligt att se data som objektiv fakta, och mer data som mer objektivt ur vilken man sedan letar efter en slutsats man har bestämt på förhand. Det kan bäst beskrivas som en irrationell tilltro till förklaringskraften hos mängden data, snarare än tillvägagångssättet datan införskaffades eller analyserades.
Forskare gör många gånger fel trots rigorös sakkunniggranskning. Nu när journalister, i värsta fall utan adekvat förståelse för metodens möjligheter och begränsningar, tar sig an uppgifter som många gånger är typiska forskningsuppgifter riskerar det att förstora upp triviala småproblem som lätt hade kunnat undvikas.
Det är dessutom ett vanligt tankefel att se sin egen grupp utsatt för hot liksom att man letar efter sådant som stödjer den egna ståndpunkten. Journalister är på inga sätt undantagna från sådana tankefel, och den lilla genomgång jag har gjort här med dessa två exempel kan vara ett sätt att se vilken slags bias journalisterna har. Med andra ord, om journalisterna redovisar hur de har gått tillväga går det att se vad för slags frågor metoden kan ge svar på och därmed också hur journalisterna lägger till sina egna tolkningar till resultaten.
Och kanske mer viktigt att påpeka, att säga journalisterna har hanterat metoden på ett felaktigt sätt innebär därmed inte att hot inte förekommer mot vare sig journalister eller flyktingar. Det är nämligen också en fallasi.
För att läsa om hot mot svenska journalister rekommenderar jag Journalism Under Threat av Monica Löfgren Nilsson och Henrik Örnebring.