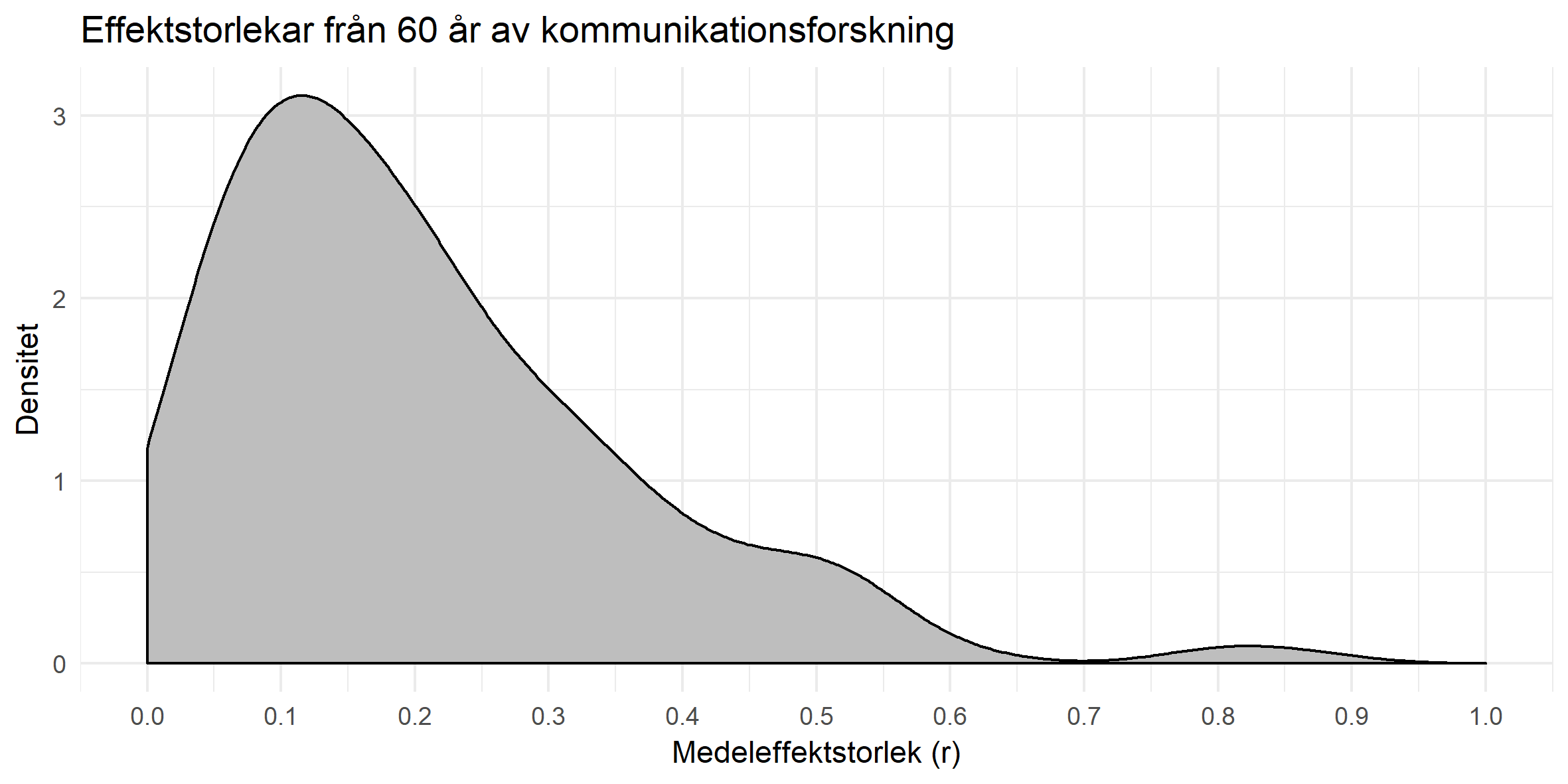
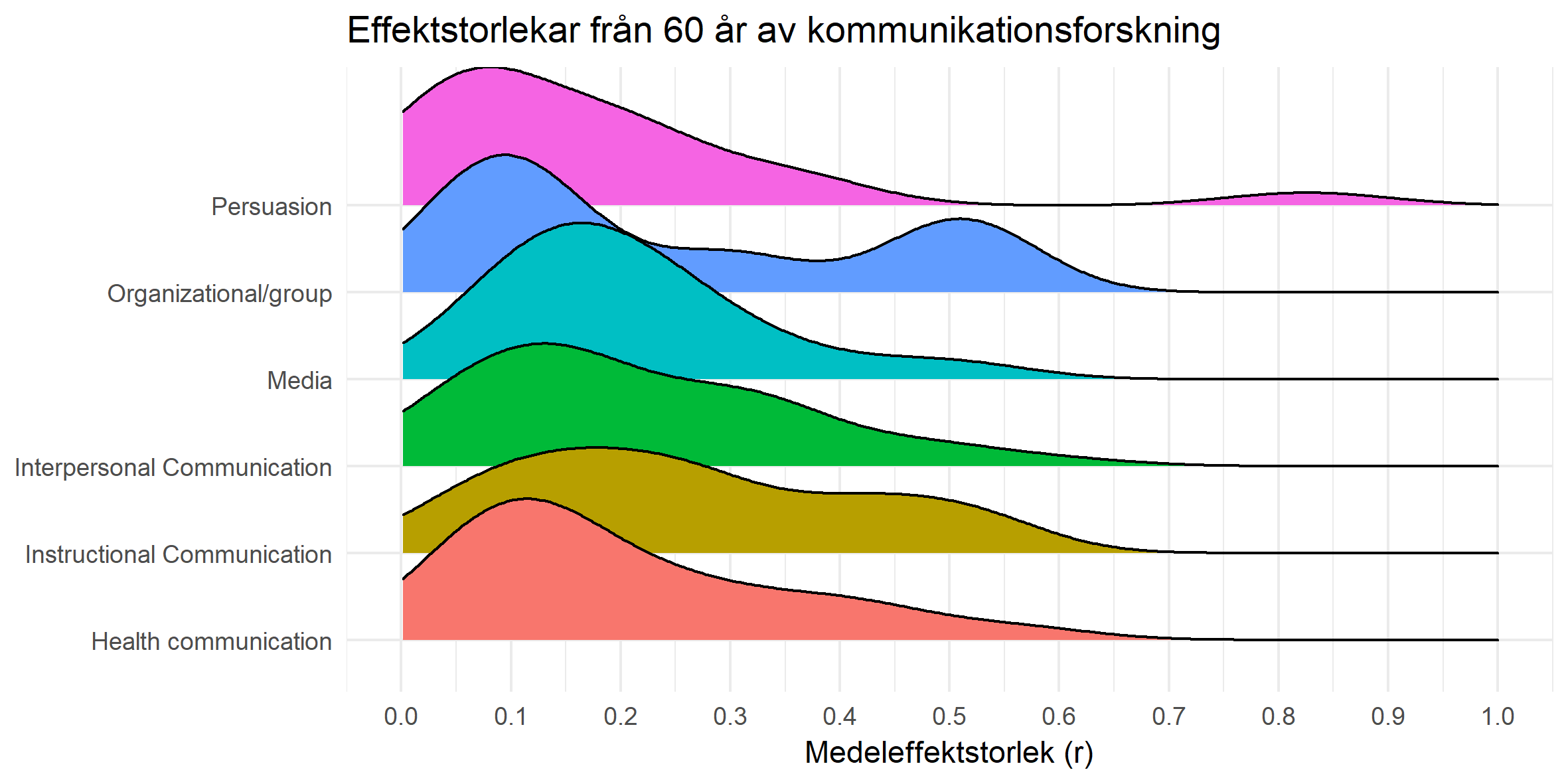
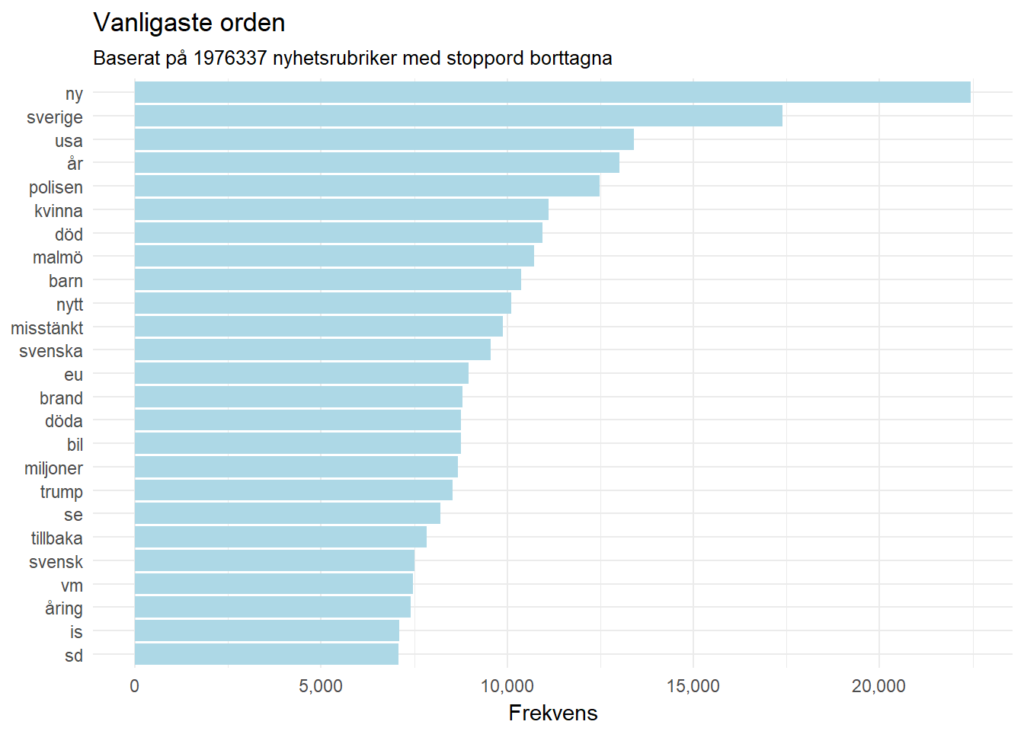
Vilka ord har ökat och minskat i bruk bland drygt två miljoner nyhetsrubriker från 2014 till 2017? I den här analysen har jag tagit nyhetsrubriker som är insamlade från början av 2014 till och med juni 2017 för att se vilka ord som förekommit mest och vilka som har snabbast ökat i popularitet.
Vilka ord har ökat mest på kortast tid? Kanske inte så förvånande är Donald Trump väldigt omskriven, precis som på Twitter. Lika lite förvånande är det ett väldigt fokus på USA och Storbritannien.
Men intressant nog verkar också vanlig lokal nyhetsvärdering öka relativt mycket, apropå ”trafikolycka” och ”singelolycka”.
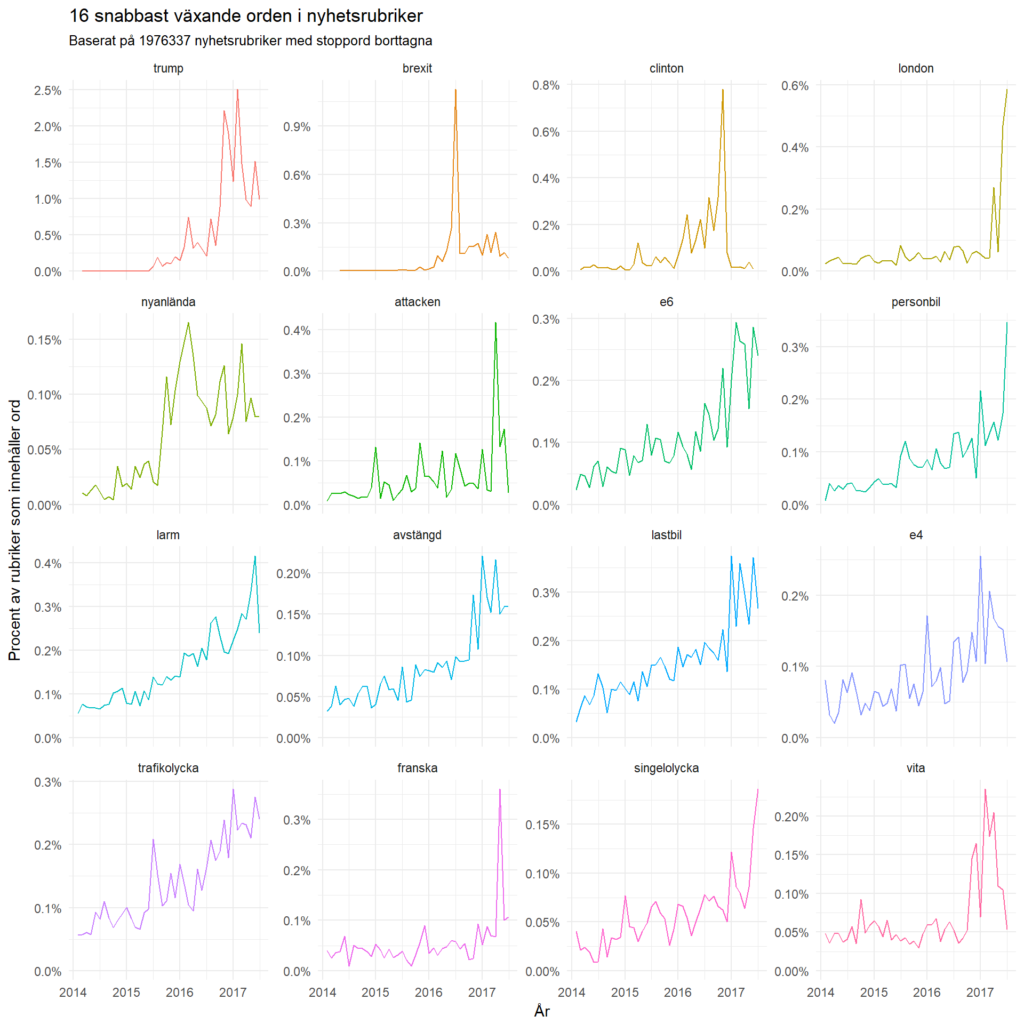
Se också de snabbast sjunkande orden.
Tittar man på de ord som ökade mest under 2015 så är det ”flyktingar”, vilket jag satt i relation till ”migrationer” respektive ”nyanlända”. Av grafen att döma verkar de svenska medierna nästan unisont börja skriva om flyktingar vid samma tillfälle, därav den vertikala ökningen av texter.
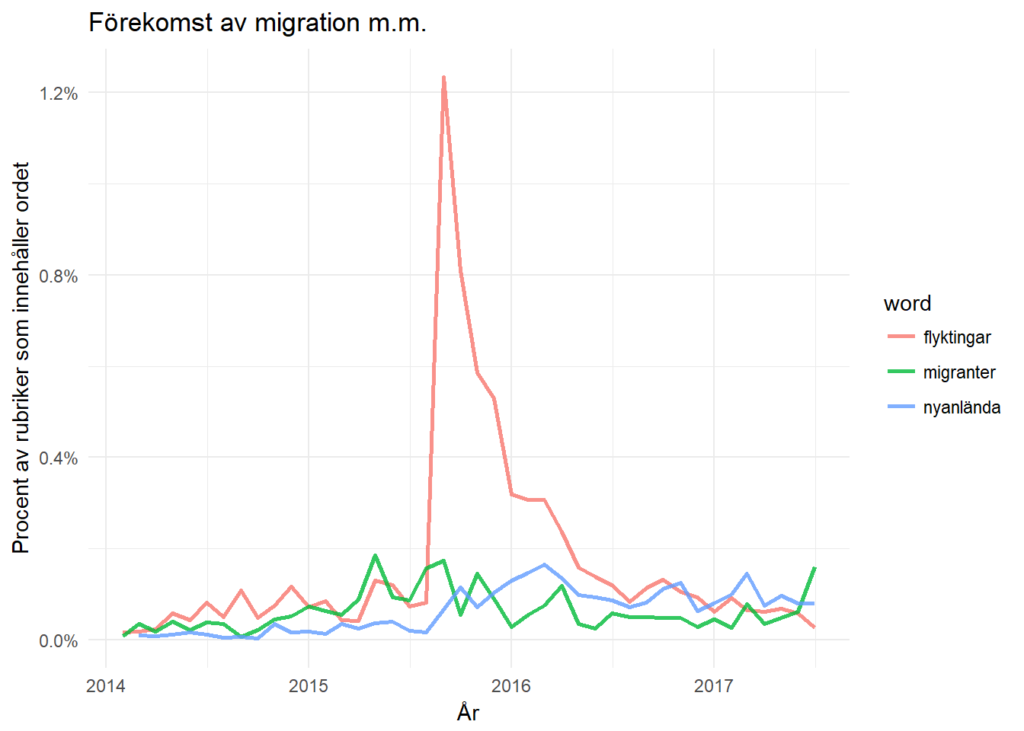
De här graferna har jag mest gjort för skojs skull, men jag tänker mig att denna typ av analyser kan vara en förhållandevis enkel början till att forska om agenda-sättning. Över lång tid ger de här analyserna väldigt intressant information jämfört med de korta nedslag som ofta görs i forskningen.
Mer intressant, tror jag, är att de också också kan användas för att identifiera var man bör starta sin undersökning (eftersom de är helt induktiva), snarare än att hipp som happ sätta upp sitt blöta finger i luften för att mäta vart vinden blåser.
Den fullständiga analysen har jag som vanligt lagt upp på GitHub där du hittar både källkod och länkar till datan som du kan ladda ned. Kom gärna med förslag på hur det kan göras annorlunda.
Fler analyser
Här är några andra analyser jag gjort i R med framför allt öppna data:
Big data i medieforskning
Att bara analysera rubriker går bra på en vanlig laptop. Det var inga svårigheter att ladda in en miljon rubriker i minnet. Vid två miljoner rubriker började datorn gå på knäna. R tog 11 gigabyte i anspråk för att köra unnest_tokens för att skapa en vektor på drygt 5,1 miljoner ord mappat till nyhetsrubrikerna.
Framöver behövs mer datorkraft för analyser av hela brödtexten, kanske med hjälp av Apache Spark som jag använt tidigare. Dock ska jag testa om bigmemory i R kan fungera eftersom den, vad jag förstår, genomför analysen på disken snarare än i minnet. Det går lite långsammare, men om man sysslar med forskning så är allt redan långsamt.
RMarkdown
Dokumenten i listan med länkarna ovan är gjorda med hjälp av RMarkdown, ett sätt att blanda källkod i valfritt språk, bilder, text och… tja, allt man kan tänka sig. Även om RMarkdown är skapat för språket R fungerar även andra språk och jag har exempelvis skrivit Python-kod i RMarkdown som jag använde som presentation under en lektion i web scraping. Det går med andra ord utmärkt att exportera till Powerpoint, Word, hemsidor eller PDF.
Det är ett behändigt sätt att paketera sina analyser. Steget från källkod till presentation blir minimalt, och det är också varför den brittiska regeringen valt att satsa på RMarkdown.
Jag tror detta kommer bli vanligare i framtiden. I stället för att presentera ett begränsat antal analyser på ett lika begränsat antal sidor så kan man dokumentera hela sin process för att låta andra upptäcka hur tankeprocessen har gått till, och även se resultat man kanske borde följa upp. Detta kan sedan bifogas till artikeln i ett appendix så att man kan se diagram och källkod tillsammans.
Frågan är vilken tidskrift som blir först med kräva att analyserna i Markdown bifogas till varje artikel? Stata 15 har ju också kommit ut med Markdown så R är ju knappast något krav längre.